
Database example
Let’s start by a simple case. Since dictionary compression is good for small data, we need an application which handles small data. For example a log record storage, which can be simplified as an append-only database.Writes are append-only, but reads can be random. A single query may require retrieving multiple individual records scattered throughout the database, in no particular order.
As usual, the solution needs to be storage efficient, so compression plays an important role. And records tend to be repetitive, so compression ratio will be good.
However, this setup offers a classic example of the “block-size trade-off” : in order to get any compression done, it’s necessary to group records together into “blocks”, then compress each block as a single entity. The larger the block, the better the compression ratio. But now, in order to retrieve a single record, it’s necessary to decompress the whole block, which translates into extra-work during read operations.

Last data point compresses records individually ([250-550] bytes)
Enter dictionary compression. It is now possible to train the algorithm to become specifically good at compressing a selected type of data.
(For simplicity purpose, in this example, we’ll assume that the log storage server stores a limited variety of record types, small enough to fit into a single dictionary. If not, it is necessary to separate record types into “categories”, generate a dictionary per category, then route each record into a separate pool based on category. More complex, but it doesn’t change the principles.)
As a first step, we can now just use the dictionary to grab additional compression (see graph), and it's an instant win. But that wouldn’t capture all the value from this operation.
The other benefit is that now, the optimal block size can be adjusted to the new conditions, since dictionary compression preserves better compression ratio (even 1 KB block size becomes practicable!). What we gain in exchange is improved performance for random read extraction.
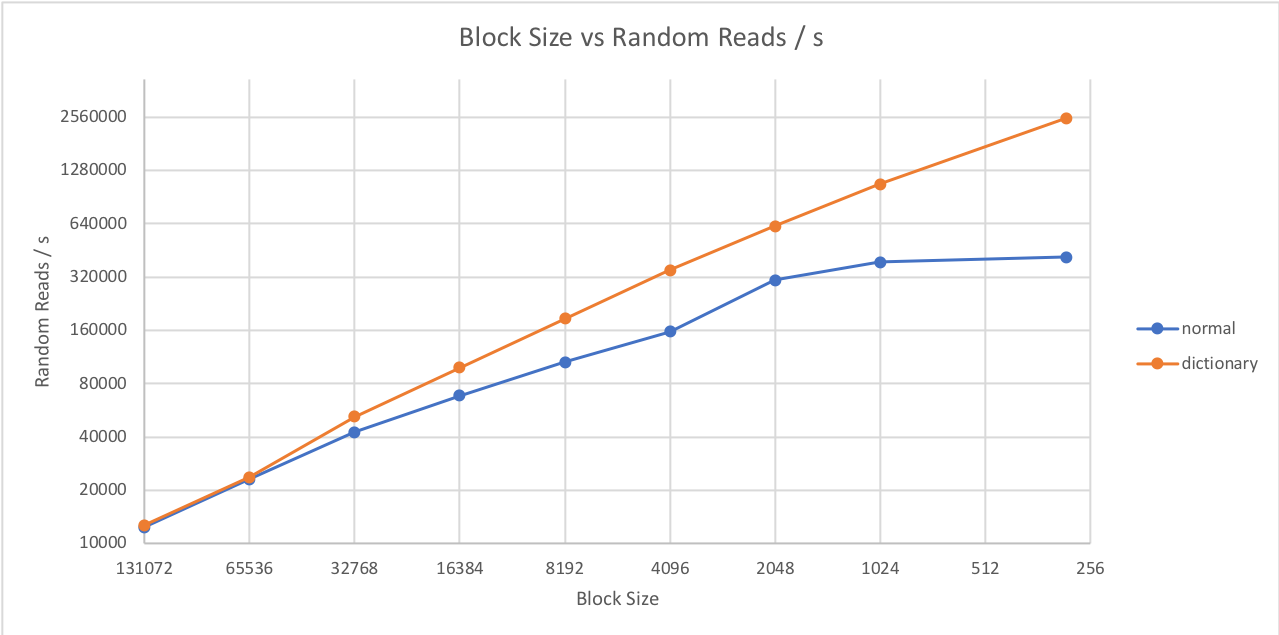
Impact of Block Size on single record extraction (Random Reads)
At its extreme, it might even be possible to compress each record individually, so that no more energy is lost to decompress additional records which aren’t used by the query. But that's not even required.
This change produces huge wins for random reads (collecting “single records” scattered throughout the database). In this example, the log storage can now extract up to 2.5M random records / second, while without dictionary, it was limited to 400K random records / second, and at the cost of a pitiful compression ratio.
In fact, the new situation unlocks new possibilities for the database, which can now accept queries that used to be considered too prohibitive, and might previously have required another dedicated database to serve them.

Normal Vs Dictionary Compression (level 1)
Comparing Compression Ratio and Random Reads per second
Comparing Compression Ratio and Random Reads per second
That’s when the benefits of dictionary compression really kick in : beyond “better compression”, it unlocks new capabilities that were previously rightly considered “out of reach”.
Massive connections
Another interesting scenario is when a server maintains a large number of connections (multiple thousands) with many clients. Let’s assume the connection is used to send / receive requests respecting a certain protocol, so there tend to be a lot of inter-messages repetition. But within a single message, compression perspective is low, because each message is rather small.The solution to this topic is known : use streaming compression. Streaming will keep in memory the last N KB (configurable) of messages and use that knowledge to better compress future messages. It reaches excellent performance, as same tags and sequences repeated across messages get squashed in subsequent messages.
The problem is, preserving such a “context” costs memory. And a lot of memory that is. To provide some perspective, a Zstandard streaming context with an history of 32 KB requires 263 KB of memory (about the same as zlib). Of course, increasing history depth improves compression ratio, but also increases memory budget.
That doesn’t look like a large budget in isolation, or even for a few connections, but when applied to 10 thousands client connections, we are talking about > 2.5 GB of RAM. Situation worsen with more connections, or when trying to improve ratio through larger history and higher compression levels.
In such a situation, dictionary compression can help. Training a dictionary to be good at compressing a set of protocols, and then ignite each new connection with this dictionary, will produce instant benefits during the early stage of the connection lifetime. Fine, but then, streaming history takes over, so gains are limited, especially when connection lifetime is long.
A bigger benefit can be realised when understanding that the dictionary can be used to completely eliminate streaming. Dictionary will then partially offset compression ratio reduction, so mileage can vary, but in many cases, ratio just takes a small hit, as generic redundant information is already included in the dictionary anyway.
What we get in exchange are 2 things :
- huge RAM savings : it’s no longer necessary to preserve a context per client, a single context per active thread is now enough, which is typically several order of magnitude less than the nb of clients.
- vastly simplified communication framework, as each request is now technically “context-less”, eliminating an important logic framework dedicated to keeping contexts synchronised between sender and receiver (with all the funny parts related to time out, missed or disordered packets, etc.).

Memory budget comparison
Context-less strategy requires much less memory (and is barely visible)
This kind of scenarios is where Dictionary Compression can give its best : beyond “better compression for small data”, it makes it possible to build target application differently, with second-order effects being as important if not more than compression savings alone.
These are just 2 examples. And I’m sure there are more. But that’s enough to illustrate the topic, and probably enough words for a simple blog post.