In an earlier post, i've presented some obvious statements about cache properties. In a nutshell, cache make tremendous difference in data access, but the fastest the cache, the smallest.
Now we are going to look more closely to its behavior.
The first important concept to keep in mind is the cache line. A memory cache does not keep in mind the last randomly accessed bytes. Data is considered structured into lines, which size depends on the CPU.
The most standard line size is 64 Bytes, that you'll find in all recent PC.
It means that whenever you are accessing a single byte in memory, you are not just loading one byte into cache, but a full line of 64 Bytes.
This is of fundamental importance. What it means is that if you ask for data at position 1, CPU will load the first line. Then, when position 2 will be needed, this data will already be in the cache, so will be position 3, and so on, up to position 63.
Given the very large difference in access time between L1 cache (3-7 cycles) and memory (100-200 cycles), it makes access to already loaded data almost free.
This is a property that any performance-oriented algorithm should keep in consideration. It requires adapted data structure.
Let's have a look at MMC and BST. They both store 2 pointers per position. These 2 pointers are stored next to each other, which means that when i will ask one, i will be able to access the other one "almost" for free.
Now, what about the data it is pointing to ?
Well, here it is very likely to fall outside of line cache, since only 8 positions are part of the same line : the next jump is almost certainly way outside of this range.
Taking advantage of cache line requires a completely different data structure. We should try to get as much hit as possible into the already loaded line, for example by keeping all level positions next to each other.
As said, this is a very different data architecture, and therefore would require a complete rewrite of search algorithm. But then, i'm here to learn...
Saturday, December 11, 2010
MMC last boost : Secondary sorting
Credit is due here to Piotr Tarsa, which made an abandoned idea for improving MMC achievable.
This idea is called "secondary sorting", and can be explained as follows :
When searching into a given level, MMC is currently merely interested by the character being looked for. Sometimes we find it immediately, and sometimes not. We may keep finding wrong characters many times, until we get to our goal.
What happens then to all these wrong characters we have discovered all along ?
Quite simply, nothing. They just stay there at their position in the chain, waiting for their turn to be looked for, if it ever happen.
It sounds like a pity, as, eventually, we could have used this information to sort all these positions to higher level, making future searches for these characters faster, but also "cleaning" the current level much faster.
However, this is a much more complex algorithm to implement. And not just complex, it's also an expensive one, requiring more structures, memory and tests. As a consequence, i was pretty much convinced that it would no reach the point of becoming worthwhile.
After a rich discussion at encode.ru forum, all problems gradually found their solution thanks to Piotr involvement and smart advises. We are now in a position where the algorithm looks reasonably efficient, and could therefore bring some benefits.
I started with a few statistics extraction, as usual, to better understand the situation.
To my great surprise, i discovered that, in many circumstances, some level can take a very long walk before finding the character being looked for. In worst circumstances, i've reach values in the thousands (probably a symptom of long repetitions). Even in more common situations, we can reach several tens attempts, with some "wrong" characters repeated many times.
It's therefore obvious that secondary sorting will provide a real boost at sorting this data, reducing the number of comparisons required for future searches.
Following this short study, i quickly implemented a limited version of "secondary sorting", just able to handle the last position of wrong characters, resulting in their anticipated promotion. It immediately resulted in a 12% improvement in number of comparisons.
Quite a large benefit for such a minor sorting improvement. Better secondary sorting can only improve this figure.
All looks for the better, except that, at this stage, the benefits do not offset code complexity.
At least not yet ...
This idea is called "secondary sorting", and can be explained as follows :
When searching into a given level, MMC is currently merely interested by the character being looked for. Sometimes we find it immediately, and sometimes not. We may keep finding wrong characters many times, until we get to our goal.
What happens then to all these wrong characters we have discovered all along ?
Quite simply, nothing. They just stay there at their position in the chain, waiting for their turn to be looked for, if it ever happen.
It sounds like a pity, as, eventually, we could have used this information to sort all these positions to higher level, making future searches for these characters faster, but also "cleaning" the current level much faster.
However, this is a much more complex algorithm to implement. And not just complex, it's also an expensive one, requiring more structures, memory and tests. As a consequence, i was pretty much convinced that it would no reach the point of becoming worthwhile.
After a rich discussion at encode.ru forum, all problems gradually found their solution thanks to Piotr involvement and smart advises. We are now in a position where the algorithm looks reasonably efficient, and could therefore bring some benefits.
I started with a few statistics extraction, as usual, to better understand the situation.
To my great surprise, i discovered that, in many circumstances, some level can take a very long walk before finding the character being looked for. In worst circumstances, i've reach values in the thousands (probably a symptom of long repetitions). Even in more common situations, we can reach several tens attempts, with some "wrong" characters repeated many times.
It's therefore obvious that secondary sorting will provide a real boost at sorting this data, reducing the number of comparisons required for future searches.
Following this short study, i quickly implemented a limited version of "secondary sorting", just able to handle the last position of wrong characters, resulting in their anticipated promotion. It immediately resulted in a 12% improvement in number of comparisons.
Quite a large benefit for such a minor sorting improvement. Better secondary sorting can only improve this figure.
All looks for the better, except that, at this stage, the benefits do not offset code complexity.
At least not yet ...
Thursday, December 9, 2010
BST : Binary Search Tree
As stated when MMC algorithm was first published on encode.ru board, there are alternative methods to search sequences in a dictionary, and one of the most efficient, to date, is BST.
BST stands for Binary Search Tree. There is a nice entry at wikipedia on this concept.
BST key idea is pretty simple : given an element, 2 pointers are associated to it. On the "left" pointers, we'll find others elements which are strictly smaller than current one. On the "right" one, all elements will be larger.
This requires elements to be "comparable", a rule we can easily create in this numeric world.
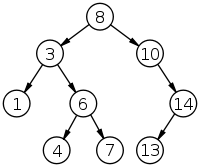
Now, maybe some of you played at the "guess my number" game as a kid. The idea is simply to find a hidden number, using a minimum number of questions, which answer can only be yes or no.
And the best strategy is always the same : if the "hidden number" is between 0-100, we start at 50, the middle number. Is it larger ? If yes, we continue at 75, if not at 25, and so on, dividing remaining space by 2 at each step.
This method will statistically provide the best result over several games.
The same can be applied here, using BST, over millions of value. In theory, it means we'll get to the result in approximately log2(N) attempts.
Except that, we can't be sure that remaining space is divided into 2 equal parts like in the game. Indeed, the tree could be "degenerated", for example when all elements are inserted in sorted order at root node, resulting in a tree which looks like a chain.
To avoid this situation, some complex mechanisms can be applied, to "balance" the tree, to ensure that all searches get approximately the same (and best) number of attempts before finding the solution. Unfortunately, such mechanisms tend to cost so much overhead as to kill performances for compression algorithms, since the dictionary constantly changes.
So, the question of this post : would BST be any superior to MMC ?
According to Bulat, yes, it should. Because its "compare" relation between parent and child nodes is more powerful than the "is next byte equal" question asked by MMC. In the end, it means that we extract more information from the BST question, and therefore we should converge faster.
But there is another big difference with BST : elements need to be sorted on insertion; while for MMC, they will be sorted during the search. It results in useless comparison operations for BST, since some elements will never be searched during their lifetime.
In a "greedy match" search strategy, this should play a role in favor of MMC, making it a faster alternative.
BST is also vulnerable to long streams of identical characters, since comparison requires more character to decide which one is smaller.
All things considered, BST is a very strong competitor to MMC, and potentially a better one.
So, save any new idea to further improve on MMC, i should spend some time on BST now, to better understand its behavior.
[Edit] I finally made a comparison between MMC and BST, and results are not so favorable to BST :
http://fastcompression.blogspot.com/2010/12/bst-first-experimental-results.html
Maybe MMC is a much better competitor than anticipated...
Wednesday, December 8, 2010
LZ4 : New version
Following yesterday's improvements on MMC search algorithm, here comes logically a new version of LZ4 "HC", for High Compression, which serves as a living demo to MMC.
It's noticeably faster, about 20% more than earlier "Fusion" version, which makes it close to 40MB/s. Not too bad considering it is a full search. The new version 0.8 can be downloaded on LZ4 Homepage.
While working on the multi-level promotion improvement, i made a small mistake in the length counter loop, which made me discover a new trick about buffer management. Thanks to this trick, less verifications are necessary, and therefore speed is a little bit increased. This trick can be re-used in many other context, and as a consequence, can be speed up LZ4 Ultra-Fast too, which make it even faster. So you'll find a new version of LZ4 too. Funny how new ideas are sometimes discovered ...
It's noticeably faster, about 20% more than earlier "Fusion" version, which makes it close to 40MB/s. Not too bad considering it is a full search. The new version 0.8 can be downloaded on LZ4 Homepage.
While working on the multi-level promotion improvement, i made a small mistake in the length counter loop, which made me discover a new trick about buffer management. Thanks to this trick, less verifications are necessary, and therefore speed is a little bit increased. This trick can be re-used in many other context, and as a consequence, can be speed up LZ4 Ultra-Fast too, which make it even faster. So you'll find a new version of LZ4 too. Funny how new ideas are sometimes discovered ...
| version | Compression Ratio | Speed | Decoding | |
| LZ4 "Ultra Fast" | 0.5 | 2.062 | 232 MB/s | 780 MB/s |
| LZ4HC "High Compression" | 0.8 | 2.345 | 38.2 MB/s | 835 MB/s |
Tuesday, December 7, 2010
Multiple level promotions : Experimental Results
At last !
God this was difficult, but finally i've completed a working version of MMC with multiple level promotions, and can now extract some useful statistics from it.
If you remember this earlier post, multiple levels promotions is about sorting the currently tested position immediately at its best level, while the previous version was limited to promoting by only one level per pass.
Being at "level L" ensure that all positions chained from the current one have at least L bytes in common. This is a pretty strong property, which greatly reduces remaining positions to test.
By promoting a position, the algorithm makes the next search for a similar pattern faster. In the end, it means less comparisons are necessary to make a full search across a file.
As usual, in order to properly test improvements, i've measured the number of comparisons required for different window size (search depth) and file types. And here are the results :
Fusion Multiple Improvement
Calgary 64K Searches 5.54M 4.86M 14%
Firefox 64K Searches 41.9M 35.2M 19%
Enwik8 64K Searches 187M 166M 13%
Calgary 512K Searches 10.9M 9.31M 17%
Firefox 512K Searches 92.1M 78.2M 18%
Enwik8 512K Searches 434M 370M 17%
Calgary 4M Searches 14.2M 12.0M 18%
Firefox 4M Searches 182M 160M 14%
Enwik8 4M Searches 751M 619M 21%
As can be seen, improvement is sensible, but not outstanding. There is a slow ramp-up with window search size, although it seems to decrease for Firefox : this is entirely due to collision hashes, which accounts for approximately 40% of all comparisons, which seems a symptom of a long enough compressed segment within the tar file.
Improvement is also relatively well distributed across all file types, and as a consequence, even enwik8 witness some solid gains for a change.
All in all, it translates into an incrementally faster search algorithm. It does not make it super-fast, but an appreciable improvement nonetheless.
Reaching higher speeds now is likely to require a completely new search methodology.
God this was difficult, but finally i've completed a working version of MMC with multiple level promotions, and can now extract some useful statistics from it.
If you remember this earlier post, multiple levels promotions is about sorting the currently tested position immediately at its best level, while the previous version was limited to promoting by only one level per pass.
Being at "level L" ensure that all positions chained from the current one have at least L bytes in common. This is a pretty strong property, which greatly reduces remaining positions to test.
By promoting a position, the algorithm makes the next search for a similar pattern faster. In the end, it means less comparisons are necessary to make a full search across a file.
As usual, in order to properly test improvements, i've measured the number of comparisons required for different window size (search depth) and file types. And here are the results :
Fusion Multiple Improvement
Calgary 64K Searches 5.54M 4.86M 14%
Firefox 64K Searches 41.9M 35.2M 19%
Enwik8 64K Searches 187M 166M 13%
Calgary 512K Searches 10.9M 9.31M 17%
Firefox 512K Searches 92.1M 78.2M 18%
Enwik8 512K Searches 434M 370M 17%
Calgary 4M Searches 14.2M 12.0M 18%
Firefox 4M Searches 182M 160M 14%
Enwik8 4M Searches 751M 619M 21%
As can be seen, improvement is sensible, but not outstanding. There is a slow ramp-up with window search size, although it seems to decrease for Firefox : this is entirely due to collision hashes, which accounts for approximately 40% of all comparisons, which seems a symptom of a long enough compressed segment within the tar file.
Improvement is also relatively well distributed across all file types, and as a consequence, even enwik8 witness some solid gains for a change.
All in all, it translates into an incrementally faster search algorithm. It does not make it super-fast, but an appreciable improvement nonetheless.
Reaching higher speeds now is likely to require a completely new search methodology.
Sunday, December 5, 2010
Early end optimization
In the course of what finally is a major effort at rewriting MMC for multiple promotions, i found a small optimization left for current MMC version.
It is simple to explain : when i know that there is no more better element in the chain, i should stop searching.
I always wanted to implement it but failed up to now, producing some missed opportunities in the pack. This is now correctly solved, with a trick called "early end".
Here are some results :
Fusion Early-end
Calgary 64K Searches 5.54M 5.52M
Firefox 64K Searches 41.9M 41.8M
Enwik8 64K Searches 187M 186M
Calgary 512K Searches 10.9M 10.9M
Firefox 512K Searches 92.1M 91.7M
Enwik8 512K Searches 434M 432M
Calgary 4M Searches 14.2M 14.2M
Firefox 4M Searches 182M 181M
Enwik8 4M Searches 751M 749M
Benefits are disappointingly low.
There must be an explanation though. If there is no possible better opportunity, we are quite likely near the end of the chain anyway, if not already at its end. With these results, it seems this was already the case most of the time.
The only good news is that this small benefit comes at no cost at all.
It is simple to explain : when i know that there is no more better element in the chain, i should stop searching.
I always wanted to implement it but failed up to now, producing some missed opportunities in the pack. This is now correctly solved, with a trick called "early end".
Here are some results :
Fusion Early-end
Calgary 64K Searches 5.54M 5.52M
Firefox 64K Searches 41.9M 41.8M
Enwik8 64K Searches 187M 186M
Calgary 512K Searches 10.9M 10.9M
Firefox 512K Searches 92.1M 91.7M
Enwik8 512K Searches 434M 432M
Calgary 4M Searches 14.2M 14.2M
Firefox 4M Searches 182M 181M
Enwik8 4M Searches 751M 749M
Benefits are disappointingly low.
There must be an explanation though. If there is no possible better opportunity, we are quite likely near the end of the chain anyway, if not already at its end. With these results, it seems this was already the case most of the time.
The only good news is that this small benefit comes at no cost at all.
Subscribe to:
Posts (Atom)