As stated when MMC algorithm was first published on encode.ru board, there are alternative methods to search sequences in a dictionary, and one of the most efficient, to date, is BST.
BST stands for Binary Search Tree. There is a nice entry at wikipedia on this concept.
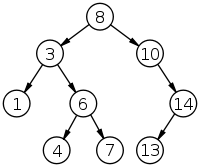
BST key idea is pretty simple : given an element, 2 pointers are associated to it. On the "left" pointers, we'll find others elements which are strictly smaller than current one. On the "right" one, all elements will be larger.
This requires elements to be "comparable", a rule we can easily create in this numeric world.
Now, maybe some of you played at the "guess my number" game as a kid. The idea is simply to find a hidden number, using a minimum number of questions, which answer can only be yes or no.
And the best strategy is always the same : if the "hidden number" is between 0-100, we start at 50, the middle number. Is it larger ? If yes, we continue at 75, if not at 25, and so on, dividing remaining space by 2 at each step.
This method will statistically provide the best result over several games.
The same can be applied here, using BST, over millions of value. In theory, it means we'll get to the result in approximately log2(N) attempts.
Except that, we can't be sure that remaining space is divided into 2 equal parts like in the game. Indeed, the tree could be "degenerated", for example when all elements are inserted in sorted order at root node, resulting in a tree which looks like a chain.
To avoid this situation, some complex mechanisms can be applied, to "balance" the tree, to ensure that all searches get approximately the same (and best) number of attempts before finding the solution. Unfortunately, such mechanisms tend to cost so much overhead as to kill performances for compression algorithms, since the dictionary constantly changes.
So, the question of this post : would BST be any superior to MMC ?
According to Bulat, yes, it should. Because its "compare" relation between parent and child nodes is more powerful than the "is next byte equal" question asked by MMC. In the end, it means that we extract more information from the BST question, and therefore we should converge faster.
But there is another big difference with BST : elements need to be sorted on insertion; while for MMC, they will be sorted during the search. It results in useless comparison operations for BST, since some elements will never be searched during their lifetime.
In a "greedy match" search strategy, this should play a role in favor of MMC, making it a faster alternative.
BST is also vulnerable to long streams of identical characters, since comparison requires more character to decide which one is smaller.
All things considered, BST is a very strong competitor to MMC, and potentially a better one.
So, save any new idea to further improve on MMC, i should spend some time on BST now, to better understand its behavior.
[Edit] I finally made a comparison between MMC and BST, and results are not so favorable to BST :
http://fastcompression.blogspot.com/2010/12/bst-first-experimental-results.html
Maybe MMC is a much better competitor than anticipated...
Also read about: http://en.wikipedia.org/wiki/Radix_tree :)
ReplyDeleteExcellent point, Piotr. Indeed, after reading this article, it seems there some obvious common points between Radix Tree and Morphing Match Chain. Probably some cousins.
ReplyDeleteRadix Tree seems like a stronger generalization of MMC. But there are two points that still need clarifications for me :
- The example provided on the wikipedia article only shows when there are just 2 choices per node. Actually, there is no explanation on how are handled 7 ou 18 choices.
It seems, from reading other articles, that the idea of Radix tree is to reach next level in O(1) time, which means, basically a table, with all choices available and easily accessible.
Since we don't want to spend a 256 positions table for each level, it requires some form of advanced "compression" or flexible allocation mechanism, making the algorithm more complex.
- Radix Tree seem fine for searching into a static dictionary. But is it still fine for a rapidly evolving dictionary ?
In particular, the "delete" operation is completely free with MMC, and also with some form of not-balanced BST.
It seems this is necessarily a more complex operation with Radix.
All in all, this is a very enlightening reading, which leads to many new ideas.
Check that: http://en.wikipedia.org/wiki/Left_child-right_sibling_binary_tree
ReplyDeleteYou'll see that tries are even closer to MMC than you thought :)
Check our thread at encode.ru. I've reposted/ edited some posts that were previously broken.
Excellent point !
ReplyDeleteYes, i knew about this conversion, but was unaware of its proper name. This is now corrected, thanks to you :)
So yes, keeping in mind this equivalence, then MMC is pretty close to Radix.
The only remaining differences are :
- We can have the same character several times at the same level. They are all "joined" together at search time (the "promotion" stage).
- MMC only produces backward-looking pointers; as a consequence, delete operation is completely free
- Obviously, memory requirement are completely different, but i guess that, for Radix, it really depends on implementation details.
oh, and i forgot this one :
ReplyDelete-Deferred sorting (sort data only if and when useful), which is probably the most curious feature of MMC.
Mostly effective with Greedy Match parsing though...